
(以下の例では、ns に 数値列が入っているという前提で解説する)
val ns=for(i<-1 to 100)yield (Math.random*1000).toInt
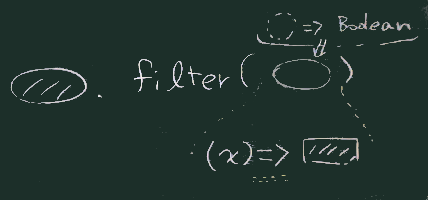 |
| filterの書き方 |
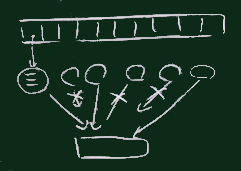 |
| filterのイメージ |
2桁の整数を選び出す
// 方法1
ns.filter((x)=>{10<=x && x<100})
// 引数x を囲む括弧や、無名関数の本体を囲むブレースは省略可
// ただし無名関数の中で x が2回現れるので、
// 引数とダブルアローは省略できない
//
// 誤りの例: 10 <= x < 100
// (不等号を続けて書ける言語は殆どない)
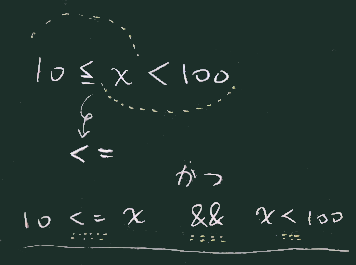
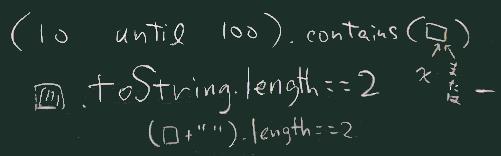

// 方法2 (以下 ダブルアローを略した記法で書く)
ns.filter((10 until 100).contains(_)
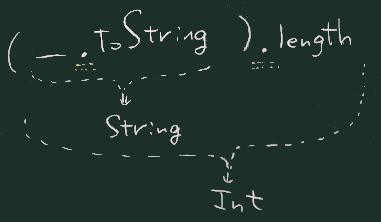
// 方法3
ns.filter(_.toString.length==0)
ns.filter((_+"").length==0)

// 方法4 フィルターのカスケード接続(メソッドチェーン)
ns.filter(10<=_).filter(_<100)
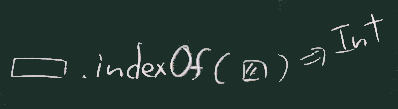
最大の数は何番目か
// 方法1
ns.indexOf(ns.max)
// 方法2
ns.zipWithIndex.max._2
タプル(2要素のタプル)の列を生成する
// 使用例:
ns.zipWithIndex.foreach{case(e,i)=>print(i+"\t"+e)}
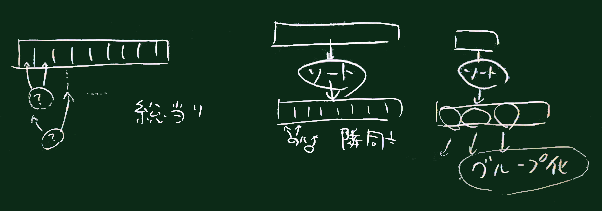 |
| 重複の見つけ方 |
といった幾つかの方法がある(右図)が、ここではその内部には触れず、
上の3.に相当する作業を請け負ってくれるメソッド groupBy の利用の仕方を学ぶ。
 |
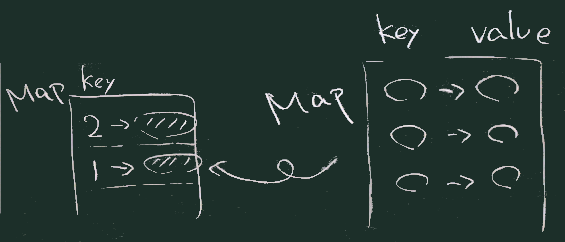
| Mapの位置づけ |
// step 1
ns.groupBy(x=>x) // groupBy(_) は使えない
ns.groupBy(identity) // identityは特殊な関数
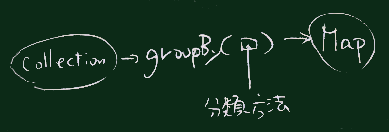
 |
| 数え上げ |
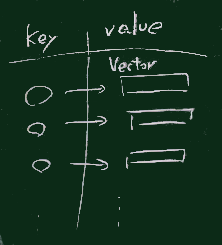 |
| keyとvalue |
Map は key->value の関係を寄せあつめたもの
(選挙の開票の作業で、人名と得票の対応表を紙などに書いていくが、その対応表に構造が似たデータ構造)
// step 2
ns.groupBy(x=>x).mapValues(_.length)
さらにグループ化してみよう
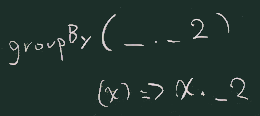
// step 3
ns.groupBy(x=>x).mapValues(_.length).
toArray.groupBy(_._2)
// step 4
ns.groupBy(x=>x).mapValues(_.length).
toArray.groupBy(_._2).
mapValues(_.length)
// or
ns.groupBy(x=>x).mapValues(_.length).
toArray.groupBy(_._2).
mapValues(_.length)(2)
 |
| 学ぶべきこと |
という方針を先生の方から提示するやりかたをとった。
ここ も参照。
タプルの列はデータとしてよく使われる
// 例1:
val z=(1,"3",4.0,(x:Int)=>x*2)
// => (Int, String, Double, Int => Int) = (1,3,4.0,<function1>)
z._1
// => Int = 1
z._2
// => String = 3
// 例2:
var a=for(i<-1 to 10)yield (i,i+"","*"*i)
for 式の <- の右辺でタプルが使える
// 使い方1
for(c<-a) println(c._3)
// 使い方2
for((_,_,b)<-a) println(b)
高階関数の引数などの中の無名関数の引数でこういう使い方をする 時には、case による記法(パターンマッチングと呼ばれる)を使う。
a.foreach{case(_,_,b)=>println(b)}
これまでに何度か例を見ている、複数の変数を1つのval式で宣言する記法も、タプルがもとになっている。
val (a,b,c)=(1,2,3)