
ASCII文字コードを中心に、すでに解説したが、以下に要点のみ再掲する。

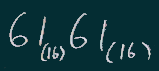
方策1:日本語文字を含む部分の直前と直後に目印を入れて区別する。
61 61 61 1b 24 42 61 61 1b 28 42
a a a ESC $ B a a ESC ( B
~~~~~~ この部分が日本語(2バイトで「瘁」を表す)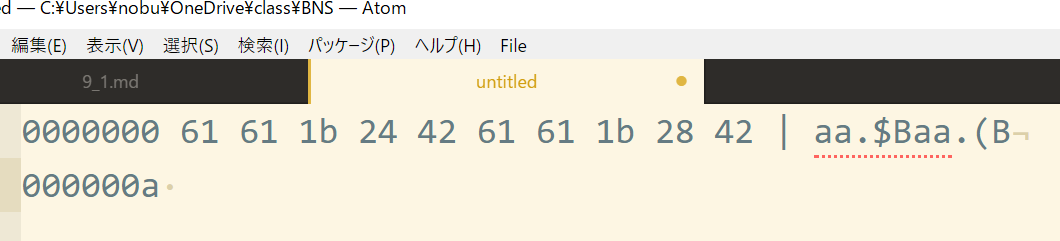 上図と右図は「aa瘁」と書いたファイル(をJISエンコーディングで保存したもの)の詳細(ダウンロードして自分で16進ダンプしてみて下さい)。
上図と右図は「aa瘁」と書いたファイル(をJISエンコーディングで保存したもの)の詳細(ダウンロードして自分で16進ダンプしてみて下さい)。
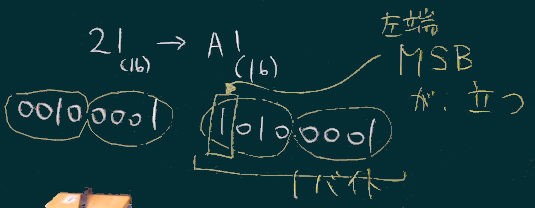
方策2:文字コードそのものに印をつける

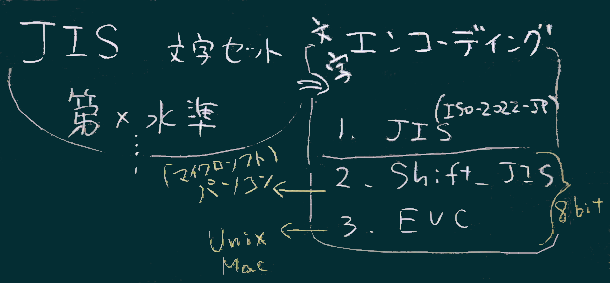
要約と余談
上記の解説は一度に読んで覚えるには煩雑すぎるだろうから、参考情報としてとどめておき、
もちろん規格を定めるだけでは日本語化は達成できない。 
PC(日本独自規格のPC以外のもの) の画面にASCII文字セット以外の文字が表示できない時代が長く続いていた状況を打破する方式として、(IBMの日本法人が開発した)DOS/V という方式が大きなインパクトとなった、という経緯があり、その名前は現在もPCの1カテゴリーを表す名前として残っている。
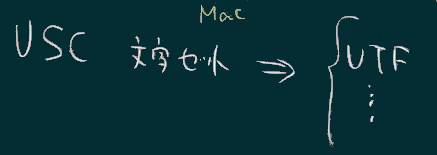
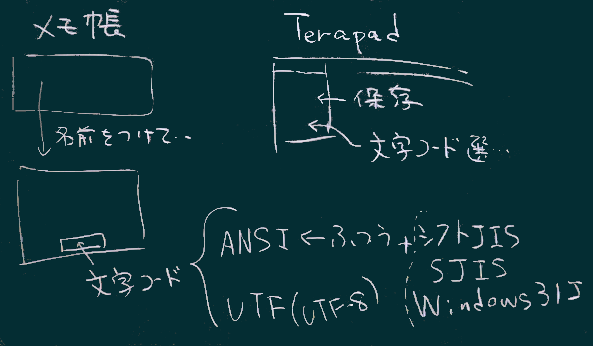
文字コード、という(やや曖昧な)用語でShift_JISやUTF-8を漠然と区別して使い分ける、という考え方で、日常の不都合はないだろう。
逆に、当初は独自規格だったものがマーケットに受け入れられ普及し、国際規格として認められるに至る過程で(中身はほぼ同じであるのに)名前が変わるという例も見てきた。
といった感じ(けっこう複雑ですよね)。

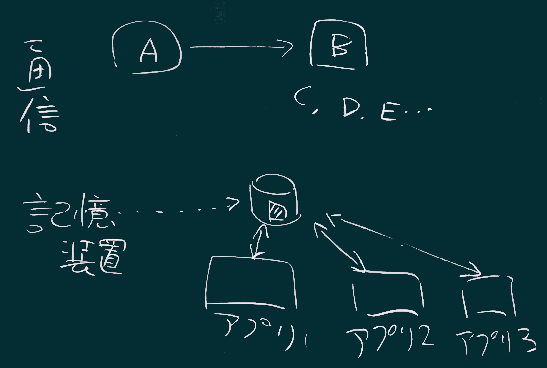
右図のように、我々をとりまく情報システムでは、ざっくり要約すると2種類の文字コード(エンコーディング;Shift_JISとUTF;図では頭文字のみ記した)が拮抗しながら使われている状況。
Windowsパソコンでネットを使うユーザのうち、ネット上の資源にブラウザ(等の特定のアプリケーション)だけを介してアクセスしている限りは(Windows とブラウザが文字の差異を適切に扱うので)問題ないが、
少し複雑なことをしたいという場面になると、この文字コードの問題が表面化するので、 若干の知識は持っておくのが望ましいだろう。