(Introduction to Informatics 2)
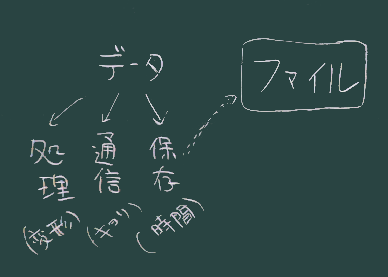
^ ^^ ^情報通信技術で「データ」が重要な役割を果たしていて、データは図のように処理、通信、保存といった操作を行う対象となってきている。 
データを「保存」(いわば時間の壁を越える)の際には、「ファイル」の形で扱うという方式が主流になっている。
1970年頃に出現した Unix オペレーティングシステム(その後のコンピュータに様々な影響を与えた)ではあらゆるものを「ファイル」の形式で扱うという考え方で作られていた。(いわば、たまたま)この選択が、現在のデータの扱い方の標準となった。

ファイルには名前がついている(利用者が名前をつける)。
名前は(人間が)その中身を推測・判断するために重要な情報となる。
名前の一部分(末尾の、最後のピリオド以降)を拡張子と呼び、コンピュータがその扱い方を推測・判断するための情報として使われていることはこれまでに見てきた 
(ただし中身と拡張子が必ずしも一致しているという保証はない)。
中身としてはデータの本体が収められているが、原則としてその中には、名前に関する情報や拡張子に相当する情報は含まれていない。
中身のデータの並び方からもそのファイルが何であるかを推測する手立ては(少しは)あることも知っておこう。
なお、ファイル名(と拡張子)に加えて、保管されている場所や最終更新日時(タイムスタンプ)、アクセス権、などの情報は、そのファイルが所属しているフォルダ(ディレクトリ)に書き込まれている。
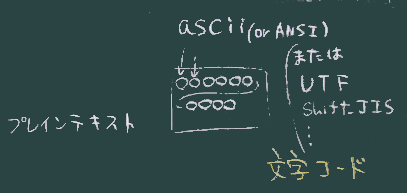
(前回、その見方をお伝えし、その実施については宿題としました。)
題材ファイル:
(ここから借用しました) これをダンプして眺めてみる。
参考資料:
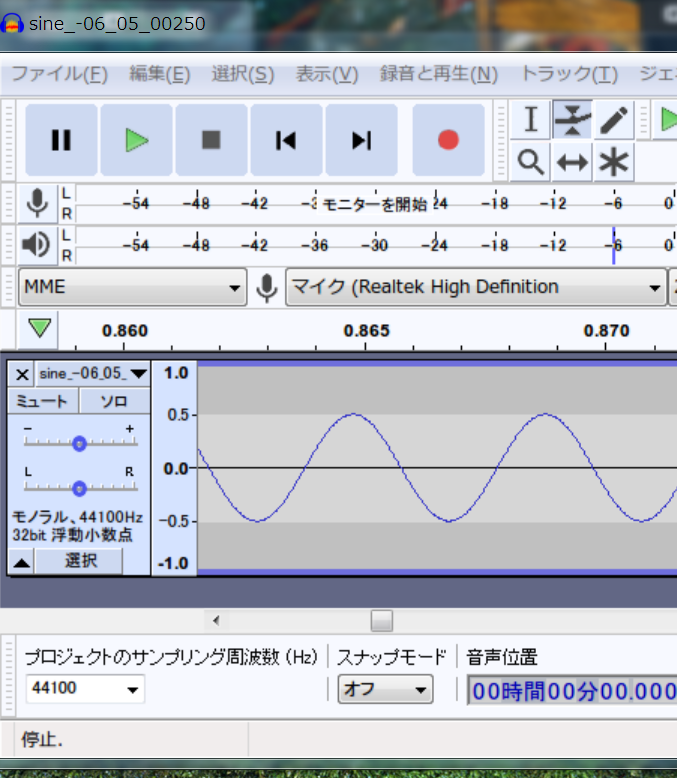
先頭部はこんな感じだろう。以下のような情報が見てとれる。


dataチャンクは 00081330H 529200バイト

このファイルは最初の0.5秒が無音期間になっているので、2441000.5 = 44100 バイト分の0がつまっている。
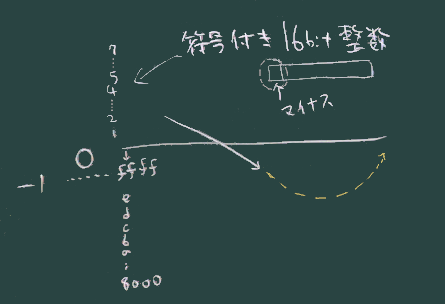
このあたりに、サンプリングされた各クロック毎の 波の高さを表す数値(符号付き16bit整数)をみることができる。
16bitの最上位の bit が符号(プラスまたはマイナス)を表す。
0 のすぐ下(マイナス1)が、ffffH で表されていることに注意。
例えば下図の 05 fa と並ぶ2バイトが1組で、一回分のサンプリング値を表し、 (左右を並び替えて考えるといい)fa05H (= -1531) がその値だとわかる。
上位バイト(各対の右側のバイト)の値の動きを見ると、なめらかに少しずつ変化していることが見てとれるだろう(右図)。 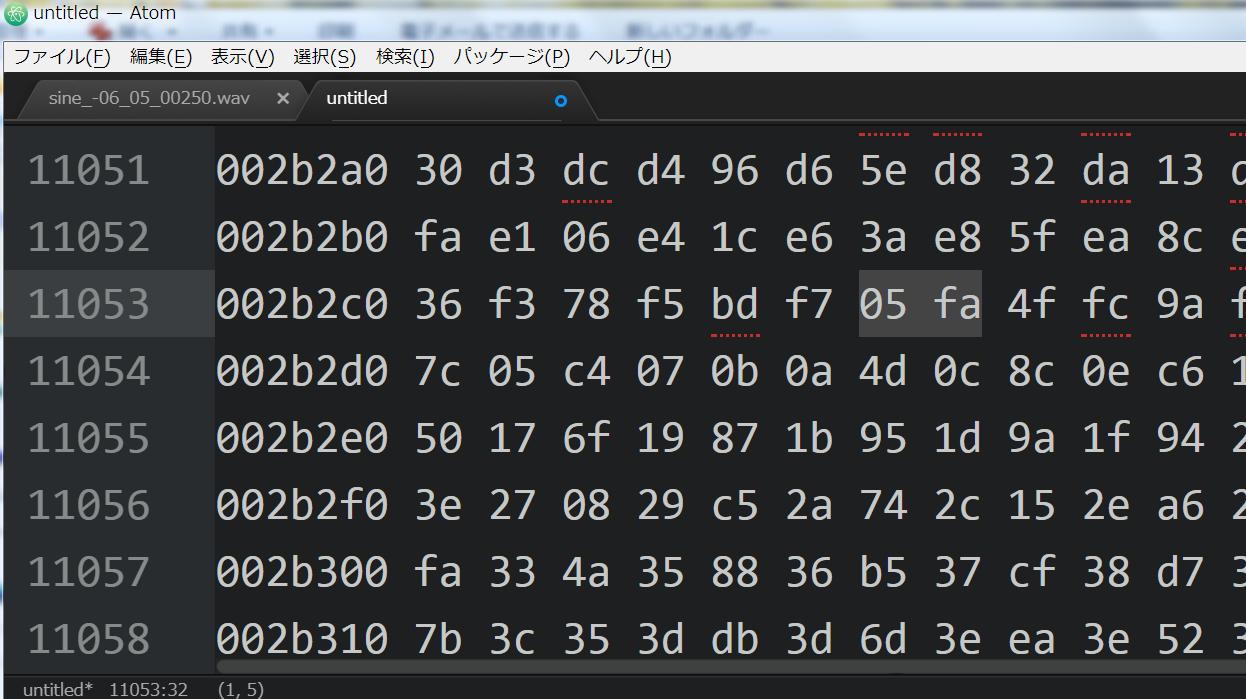
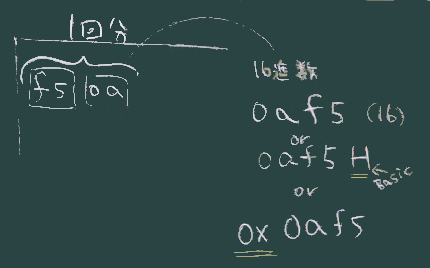
データの形式変換には、様々な選択肢があるので各自で探してみて下さい。
実習: 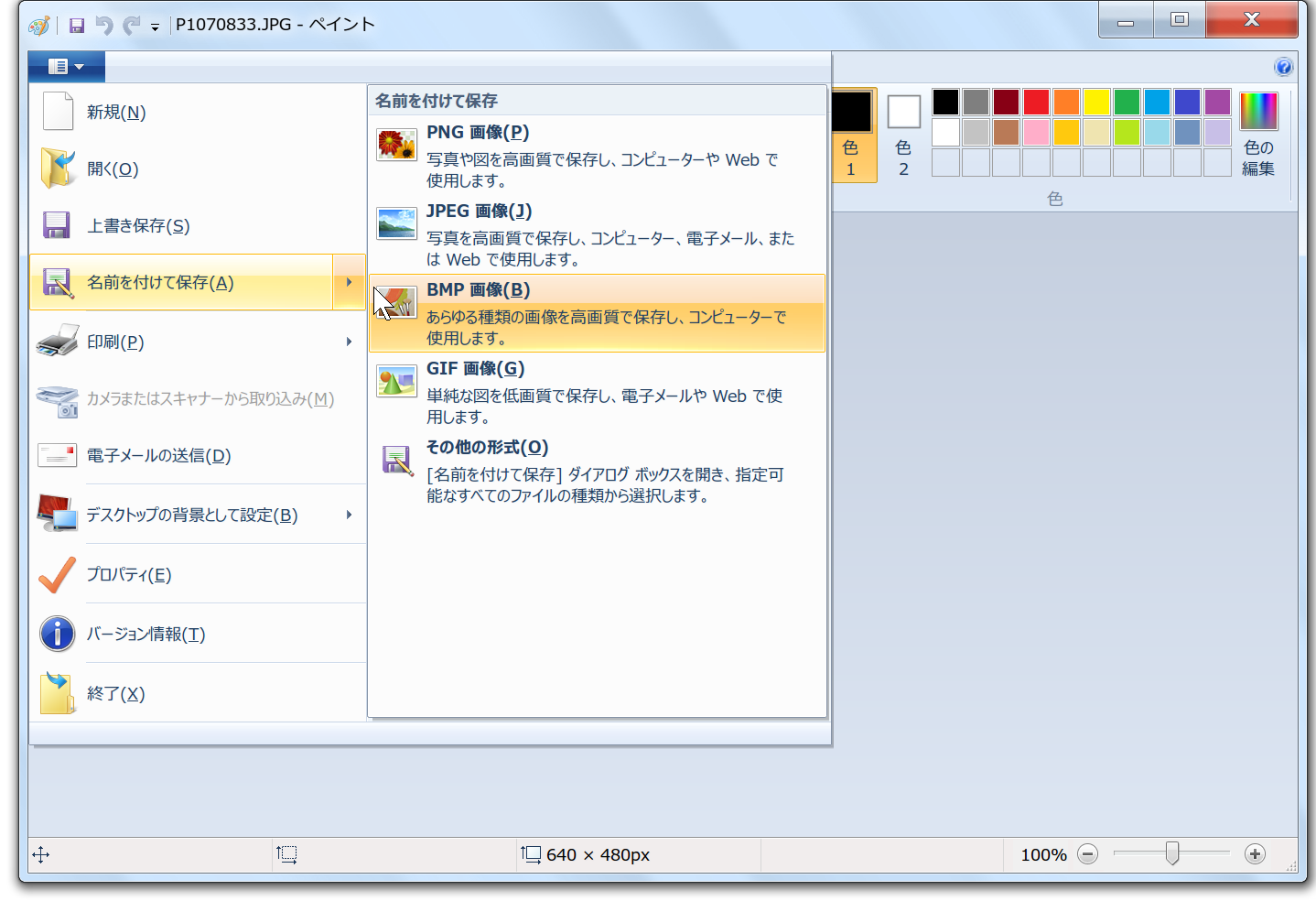
(考察、計算、実験)
(調査、実証)以下の2つ、実際にやってみて下さい。
例題として(せっかくなので古典から題材を得ました)用意したテキスト(これ; .txt または これ;.md)を、
HTML ファイルを1つ作成し、その中に組み込む(または .md にしてから変換する)。
<meta charset="utf-8"/> を先頭部に入れておくといいかもしれない。縦書きで表示する。(どうやって?)
いくつかの難読(でもない?)漢字にふりがなをつける。

の順に操作して、右図のようにブラウザで表示させてみて下さい。
ブラウザによって動作しないとか別のCSS属性を使う必要がある、というケースもあります(特にIE)が、
Chrome, Firefox, Safari などで表示できればよしとしましょう。
=> 本節は次回
2次方程式の解法を要約したページ。これも、HTMLファイルを1つ作ってみて下さい。
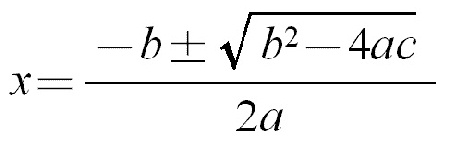
参考に、LaTeX での数式の書き方を以下に抜粋します。
| 式 | (英語) | 書き方 |
|---|---|---|
| 分数 | fraction | ¥frac{a}{b} |
| べき乗 | power | a^b |
| 平方根 | squre root | ¥sqrt{a} |
| プラスマイナス | plus minus | ¥pm |
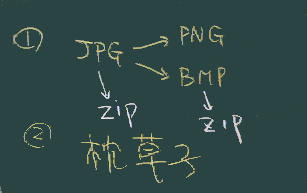
1章で添付した実習用画像それぞれについて、
といった作業をしてみて、(そのファイルサイズ等について)気がついたことを報告ください。
2.1節(枕草子) について、自分で調べてみてわかったこと、自分がどんな方法を使ったか、 について報告ください。 (作ったHTMLファイルも添えて提出)
{kind=link}
{kind=link}