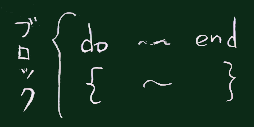
Programing Language
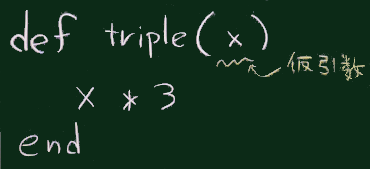
{|r,e| r+e}
のように、 縦棒で挟んで変数名(と同等のもの)を並べることがある。
{|e|....}が渡されたときは、
「配列の、個々の要素を取り出して e と名付けたとき、 ….の式を評価した値」
という意味になる。 
Ruby, Scala, Lisp などの言語では(明示的な指示がなければ)ブロック内に並んだいくつかの式の中で最後の式(ブロック内に含まれる式が1つならば必然的にその式)の値がブロックや関数の値として採用される(そのため return文は使われないことが多い)。

配列要素に対して繰り返すメソッドは 以下のようなものがある
(実はもっといろんなバリエーションがあるが
ここではその中で根源的なものを4つ紹介する)。
| each | for による記法と同等の動作 |
| もとの配列を値として返すので ブロックの中で | |
| 何かの作用を起こすという使い方をする | |
| map | 新しい配列を生成して返す |
| 新しい配列の各要素の値は もとの配列の各要素に ブロックを適用した結果 | |
| select | 条件を満たすものだけを選択して 新しい配列を作る |
| reduce | 集約値を得る |
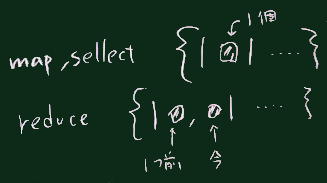
map select reduce といったメソッドは Arrayの1つ上の Enumerableモジュールに定義されている
reduceは 使い方として
の2つがある。(他のメソッドも同様)
これらのメソッドは、基本的には配列のすべての要素に対して同じ処理を施す ものなので、不均一な(要素の型がまちまちな)配列に対しては エラーを起こしやすい(暗黙の型変換が有効な場合もあるが)
これらのメソッドは、 ブロックつき呼び出しを行うことが前提になっている。
なお、(これはRubyに不足しているものとしてよく語られるものだが) 昨今の言語には「内包表記」という記法が用意されることが多い。
注)従来の手続き型言語では
n=a.size
i=0
while i < n do
puts a[i]
i+=1
endのような記法もあるが、本科目ではこういう書き方はなるべく避け、 関数とメソッドの呼び出しを活用してコンパクトに書くことをめざす

各要素にメソッドを適用し、新たな配列を生成 (右図2は前回の例題のデータの流れ)
a.map{|e|e*3}補注) 
map は、Enumerableモジュールに定義されている。

mapとは別に、map! というメソッドがある(こちらは Arrayクラスに定義されている)。
map(などここで紹介する高階関数)は、それぞれ ブロックをつけないで呼び出す記法も用意されている。

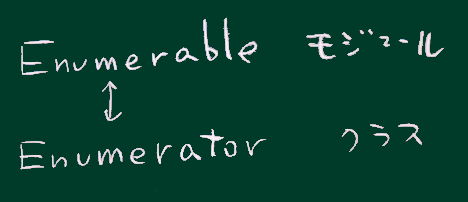
mapを使った実演例
(0..30).map{|e|2**e}
# => 2のべき乗の数が並ぶ配列この中から、2の30乗がどれであるか、を見つけ出すのは けっこう煩雑になるだろう。そこで、
(0..30).map{|e|2**e}.
each_with_index.to_a
# => 乗数が横に付随したタプル並ぶ配列または、
(0..30).map{|e|2**e}.each_with_index{|e,i|
puts "2 no #{i} jou wa #{e}"
}のように表示させる、などの、アジャイルなプログラムが書けると便利だろう。
条件を満たす要素だけを選んで配列を生成 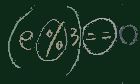
a.select{|e|e%3==0}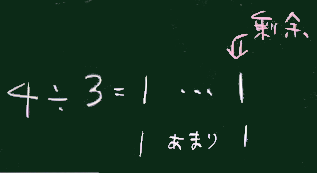
補足:
1+2+3 は 2つの演算子 + が同じ優先度なので、
「左結合」という規則により (1+2)+3 と解釈され、1+2*3 という式だと + と * では 後者の優先度が高いので、
1 + (2*3) と解釈される(小学校の算数で習った通り)。 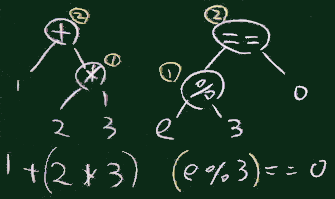
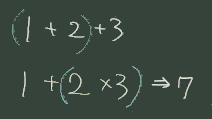
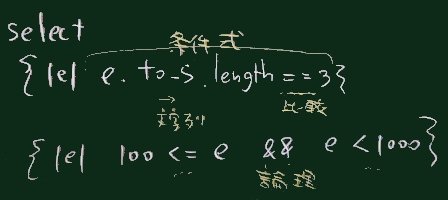
(または .inject(言語によっては foldとも呼ぶ)) 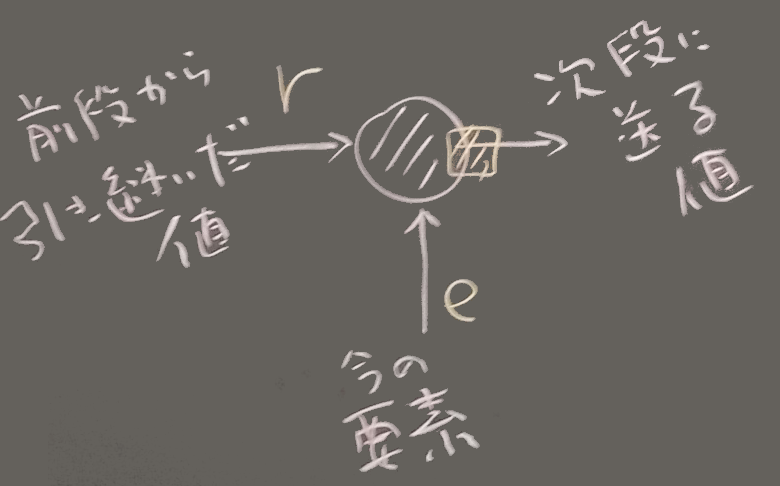
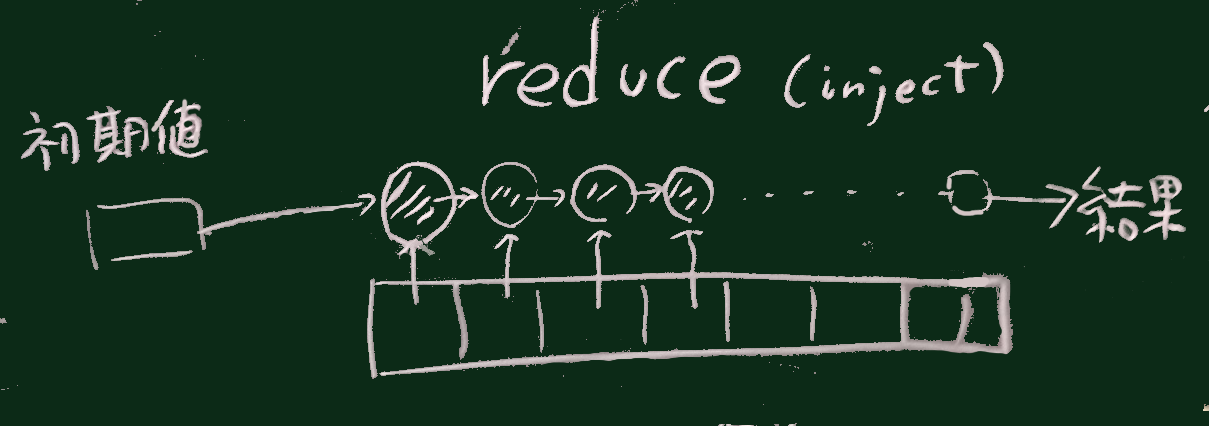
後置するブロックは2引数で、
初期値を省略したときは初期値として最初の配列要素を使う
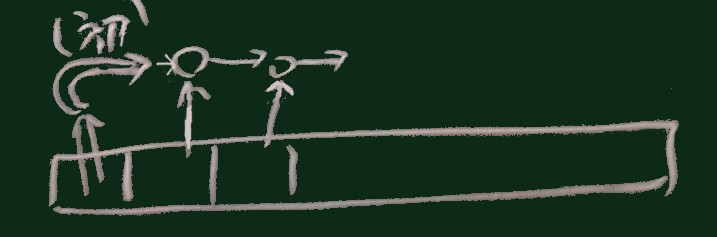

このときは、最初の配列要素が r と同じ(または変換可能な) 種類である必要がある。
a.reduce{|r,e|r+e}
a.reduce(0){|r,e|r+e}一般論としてRubyでは配列の中に様々な種類のデータが混在できるが、
混在する配列にReduceを適用した時にはエラーが起きる可能性が高い(ことは容易に想像ができるだろう)。

なお、Reduce(という英単語)は、 「減らす」というような意味であるが、数学的には「縮約」などと訳される
上記の例でブロック変数に r, e といいった文字を使っているが、

 (右図のように、他の単語も使われるが、 Itemの i は
Integerの時に使われることが多い文字なので
ここでは避けられることもある)
(右図のように、他の単語も使われるが、 Itemの i は
Integerの時に使われることが多い文字なので
ここでは避けられることもある)なお、reduceに渡すブロックの中では、2つの引数を両方使った式を用いるのが普通
a.reduce{|r,e|r} => a[0] # 最初の要素の値
a.reduce{|r,e|e} => a[-1] # 最後の要素の値2引数の演算子がここでの対象

演算子(または文字列)の先頭に :をつけてシンボルを作る
集約値を得る簡易な記法である
この使い方の時は、rとe は同じ種類のデータである必要がある (ということはその演算の結果も同じ種類である必要がある)。
a.reduce(:+)
a.reduce(0,:+)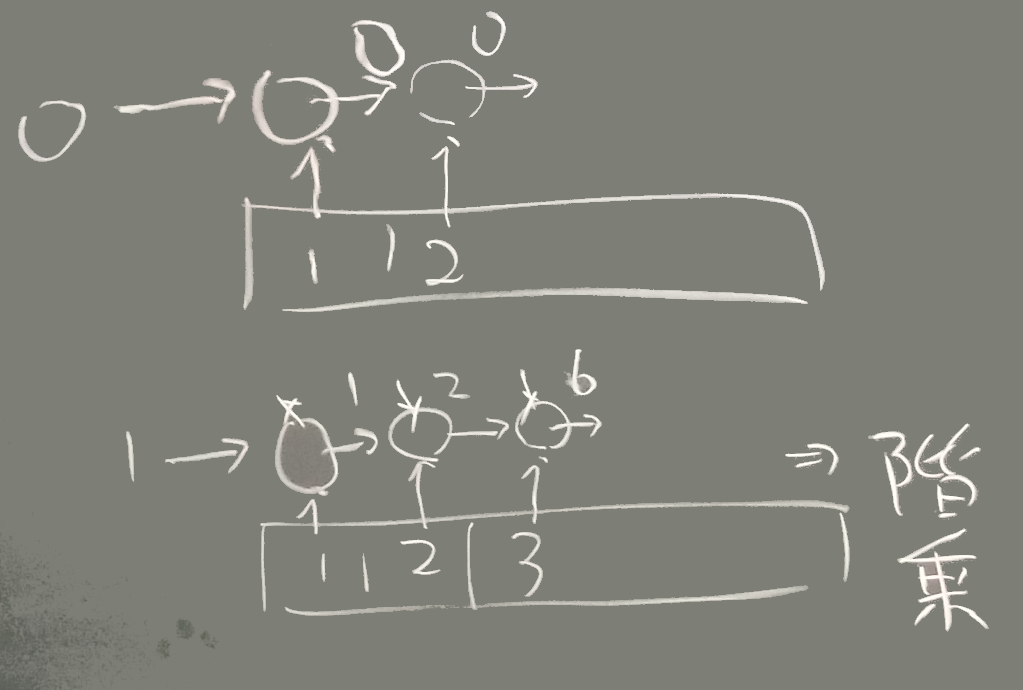
この記法で(括弧を省略できるのは以前に説明した通り)、

(1..5).reduce(:+)また、非常に値の大きい結果を生成する「階乗」のような計算も楽に書ける。
(1..100).reduce :*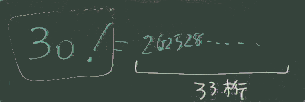
たとえば30! (30の階乗)の結果は33桁の整数になる (以下の式で確認できる)が、Rubyでは桁あふれを起こさず 整数として計算できていることも確認されたい (他の多くの言語では実数として近似計算しかしないが)。
(1..30).reduce(:*).to_s.length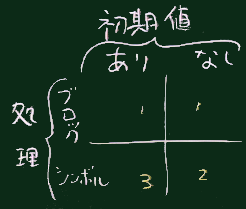
階乗のような計算をさせるときに、(総和を求めるときと同様に) 初期値に0を与えるとどんな結果になるか考察せよ。
上記の 3 と 3’ は リファレンスマニュアルの当該ページに 別名の inject を除いて3つのパターンが書かれている。 右図のように整理して理解されたい。
reduceに渡すブロックで、各要素の値(上記の例では
e)から、 違う型の値を生成する式を使う場合、
初期値なしの形で呼び出すとエラーとなることが多い ( a[0] が初期値として
最初の呼び出しで r に渡されるから)。
右下図下のように初期値を与えて使うこと。 
設問1から100までの数を4乗した数の列の中で、 (どこかの桁に)6という文字を含むものだけを選び出す
例:
| 1**4 -> 4 | × | |
| 2**4 -> 16 | ○ | |
| 3**4 -> 81 | × | |
| 4**4 -> 256 | ○ | |
| 5**4 -> 625 | ○ | |
| … |
=> 16, 256, 625, …
この節には、順を追って プログラム例が示されているが、なるべくここを見る前に 自分で解いて見ること
‐‐‐ (以下はあとで見て下さい)
1..100
(1..100).to_a
(1..100).to_a.map{|n|n**4}
(1..100).map{|n|n**4} # これでもいい
[*1..100] # ややマニアックな書き方(慣れると心地いい)
1296.to_s # 数値を文字列に変換する
1296.to_s.include?('6') # ある文字列を含むかどうか(1..100).map{|n|n**4}.select{|nn|nn.to_s.include?('6')}
# もしくは もとの数を配列にする
(1..100).select{|n|(n**4).to_s.include? '6'}(1..100).select{|n|(n**4).to_s.include? '6'}.
map{|n|"#{n}**4 => #{n**4}"}(1..100).select{|n|(n**4).to_s.include? '6'}.
map{|n|"#{n}**4 => #{n**4}"}.
join(', ')本節は、各自で(マニュアルを参照しつつ) 試してみて下さい。
(既出のものも含む)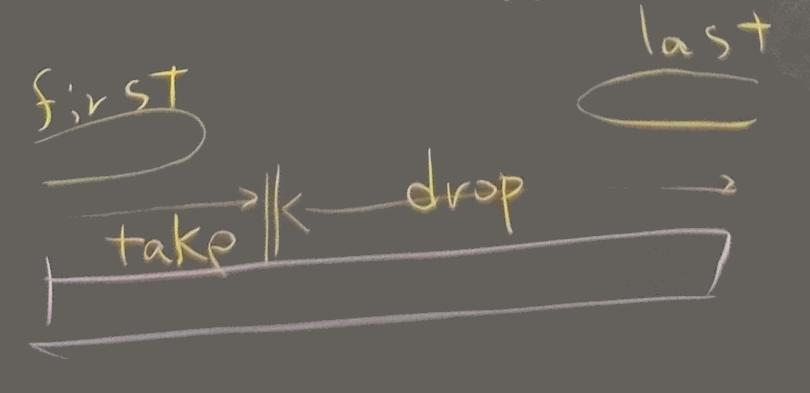
.join |
つなぐ(これは既出) a * ‘,’ という記法もある | |
.size or.length |
長さ ( 〃 ) | |
.dup |
# DUPlicate = 複製する | |
| # 破壊的メソッド(配列に変更を加えるメソッド)を使う時は | ||
| # 予めdupしておくのがいい |
| Enumerable#first | <-> | Enumerable#.last |
| Enumerable#drop | <-> | Enumerable#take |
| Array#sample | ||
| Enumerable#sort | Enumerable#sort_by | |
| Enumerable#zip (ary1, ary2,…) | # zipper とか zip loc の zipです |
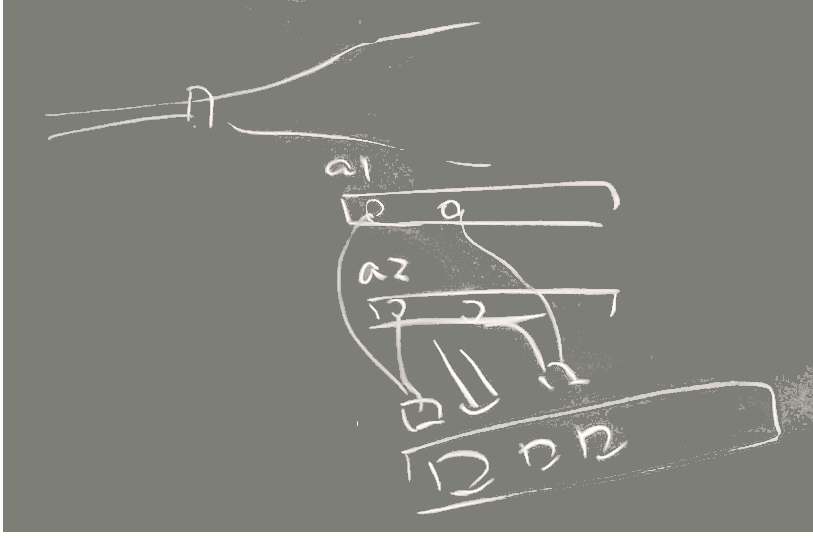
.index .find .find_all
.reverse .rotate .shuffle
(数学で昔ならった順列と組合わせに関連する)
.permutation .repeated_permutation .combination .repeated_combination .product .cycle

# 注)
出発点となる配列のサイズが大きくなると、生成される配列が
#
爆発的に大きくなる(場合によってはPCが止まってしまう)ので注意
組み換え
Enumerable#each_cons Enumerable#each_slice Enumerable#partition
| 参照 | 添字を1つ指定 | |
| 始点添字と数を指定 | ||
| 代入(!) | 添字を1つ指定 | |
| 始点添字と数を指定 | 伸び縮みする | |
| 範囲を指定 | 〃 | |
| 抜出し(!) | 先頭 末尾 位置指定 | |
| .shift .pop .delete_at | ||
| 値を使うことが多い | ||
| 追加(!) | 先頭 末尾 位置指定 | |
| .unshift .push (または «) .insert |
1~100からなる配列
(1.の配列について)各要素を3倍する
(1.の配列について)3の倍数だけを選び出す
a’ ~ ’z’までの文字列からなるサイズ26の配列
[1, 2, 3, 1, 2, 3, …] と繰り返す サイズ20の配列
乱数からなる配列を作る 補足:
rand => 0 以上 1 未満の実数を返す
rand(n) => 0 以上 n 未満の整数を返す
rand(6)+1 => 1から6の間の値をランダムに(サイコロの働き)最大のものを見つける  (a.max
と書けるのだが今日はreduceを練習して下さい)
(a.max
と書けるのだが今日はreduceを練習して下さい)
注) 式0 ? 式1 : 式2 は if式と同じ意味の
3項演算子的な表現(CやJavaにもあるのと同じ)。
ただし ? の前にスペースが必要。
これは rubyでは ? も名標(変数名など)に使える文字だから「最大のものを見つける」ことができたら、次に、 「最大のものは何番目にあったか」を求めてみて下さい。