

右図のような、文字列 a について、
を調べる時は、String#slice、String#indexや String#include?
メソッドが使える。ところが、 
(図では○で表した)「何でもいい1文字」を表現する方法(と、それを処理するメソッド)があれば、
検索するときの表現力は増すだろう。(それが「正規表現」です)
文字列 a の中で、「1 □ 3」のような並びを見つけるためには(Rubyでは)
a.index(/1.3/)
# または
a =~ /1.3/と書く。 
String#index は前に紹介した時には文字または文字列を渡す使い方だったが、
今回は正規表現(RegExpオブジェクト)を渡している。どちらの使い方もできるメソッド。
同様に、引数として正規表現を渡すことができるメソッドがStringクラスに多数あるので リファレンスで確認しておくこと(右板書図)。

=~
の両辺に、マッチさせたい文字列とパターンを置いて使う。 
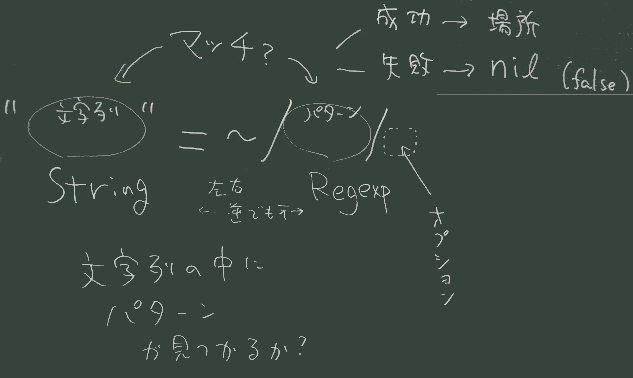
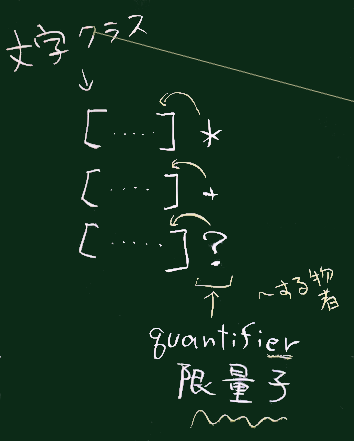

| 文字クラス | [0-9] または \d |
| その繰り返し | [0-9][0-9]*, [0-9]+,
\d+(いずれも同じ意味) |
* |
直前の表現の0回以上の繰り返し |
+ |
直前の表現の1回以上の繰り返し |
| (これらは量指定子または限量子と呼ばれ、 | |
| 直前の表現を修飾する形で使われる;右図参照) |

^ と $ |
(アンカー)マッチ対象の 先頭^ と 末尾
$(下図) |
|
() で囲んだもの |
後で $1 $2
などの文字で参照できる(後方参照) |
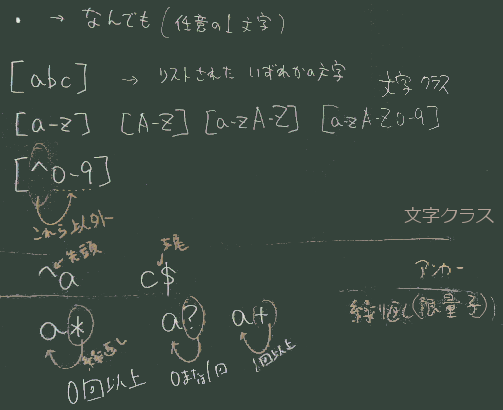
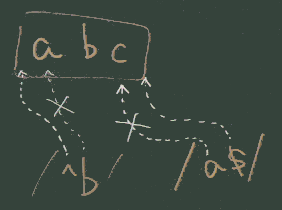

| / … / | : | スラッシュで囲む |
| / … / =~ line | : | 演算子 =~ を使って 対象文字列とのマッチング |
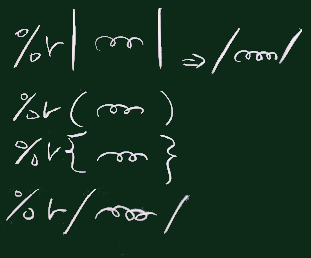 文字列 と 正規表現(で 書かれた「パターン」) との間の
「マッチング」が試みられる
文字列 と 正規表現(で 書かれた「パターン」) との間の
「マッチング」が試みられる
例:
”alphabet” =~ /ab/
# 文字列の中に ab という文字の並びがあるかどうか =~ が マッチングの演算子(右辺は文字列 左辺はパターン
その逆も可)
パターンが見つかれば 見つかった場所(何文字目か)を値として返す
見つからなければ nil
スラッシュで囲む代わりに他の文字で囲むための記法(%記法)もある。
パターンの末尾にオプションを指定することもできる。
/abc/i と書くと、
大文字小文字を区別しない(case-insensitive)マッチが試みられる。 
マニュアルのチェックしておくこと。
正規表現リテラル、
%r記法、
正規表現、
=~
演算子(メソッド)
s="abcdefg"
s=~/a/ => 0 a が見つかる(0文字目に)
s=~/ef/ => 4
s=~/x/ => nil 見つからない(マッチしない)

^ |
キャレット(caret) 山型記号 | |
$ |
ダラー | |
~ |
チルダ(tilde) にょろ |
その他の文字も「特殊記号 読み方」などで検索すれば情報が得られます (例えばこのページ)。
サンプルデータファイルをダウンロード
(自分がコマンドプロンプトで作業をする予定の場所 に 保存する
ファイル名は WORDS.txt とする)
コマンドプロンプトで irb を起動する
(以下は irb上での作業)
(w=IO.readlines('WORDS.txt').map{|e|e.chop}).size
# これで 配列 w(正確には 変数wが保持するArrayオブジェクト)に
# 2万数千個の英単語(String型)が入っているまたは
(w=open('WORDS.txt'){|f|f.gets(nil).split}).size
(w=IO.foreach('WORDS.txt').map &:chop).size
(w=IO.read('WORDS.txt').split).size
# というふうにいくつかの書き方がある
w.grep(/X/)
w.grep(/abc/)などで その中からパターンにマッチする単語を抜き出して表示する。
出力されるものが多すぎる(ために画面が流れていってしまう)時は、
w.grep(/a/).sizeなどで そのマッチした数だけ表示させてみるといい
以下の条件を満たす単語がいくつあるか調べて見る
hint:
解答のページはあとで(しっかり考えてから)見てください。