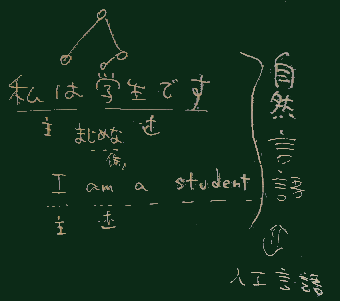
全体の流れ
scan() ->[トークンのリスト] -> parse() -> [構文解析木] -> calc()自然言語(日本語や英語など)でも、それを理解するために構文解析(parsing) は行われる。
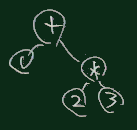
数式を解析した木の場合、下図のような形のものができる。

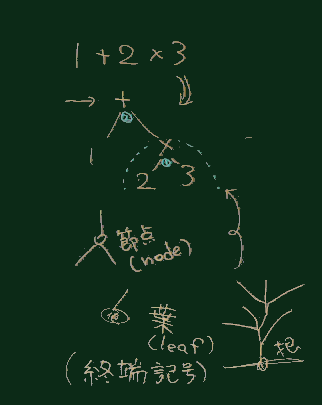
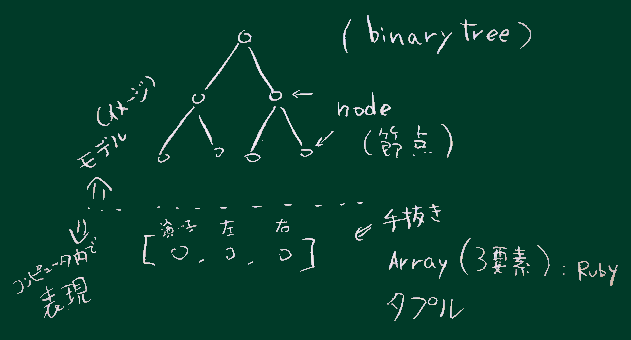
 (即時計算の時と同じ考え方)
(即時計算の時と同じ考え方)
以下を繰り返す
トークンリストから、left op right の3つを取り出す
取り出したものが left だけであれば繰り返しを終了
3つをノードとして1つのデータ(ここでは配列)にまとめ、
トークンリストの先頭に書き戻すプログラムとしては以下のような形になる
while (left, op, right = tokenList.shift(3)) and op do
tokenList.unshift [op, left, right]
end
p left # ここに構文木が作られている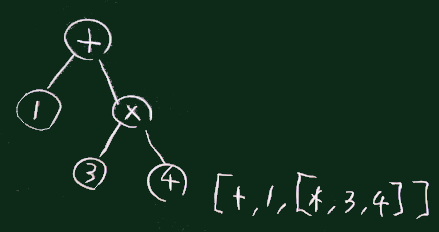 右下図に示す構造になる。
右下図に示す構造になる。
この形ではプログラムに発展性がないので、 トークンを1つずつ取り出して処理するプログラムにしてみる。 (ただし数式の文法違反の検出は当面は行わない)
トークンリストから予め1つ取り出して left に置いておく
トークンリストから1つずつトークンを取り出して以下の処理をする
トークンが 演算子ならば op に置いておく
トークンが 数値ならば、(そのトークンを最新トークンとすると)
op left 最新トークン でノード(構文解析木のノード)を作り、
left に置いておく
 先のプログラムでは変数を2つ(left, op) 使った
(rightはすぐに消費するため使わなかった)が、
代わりに、スタック(LIFO型の1次元データ構造)を使う。
先のプログラムでは変数を2つ(left, op) 使った
(rightはすぐに消費するため使わなかった)が、
代わりに、スタック(LIFO型の1次元データ構造)を使う。
スタックは、rubyではArrayで実現できるが、 
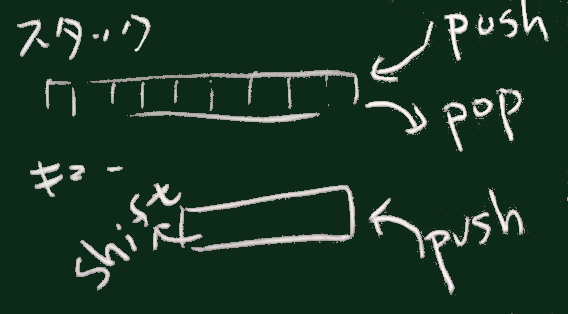
push, pop の2つのメソッドだけを使う (ここでは、プログラムを作る人がその制限のもとにコーディングする)。
すなわち、Arrayの末尾側の末端でのデータ出し入れだけを行うことになる。
a=[] ; a.push tokenList.shift
while t=tokenList.shift do
case t
when Symbol then a.push t
# 演算子はスタックに積む
when Numeric
a.push [a.pop, a.pop, t] # 3つ組を積む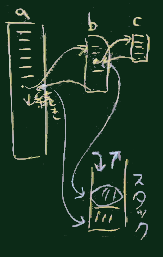
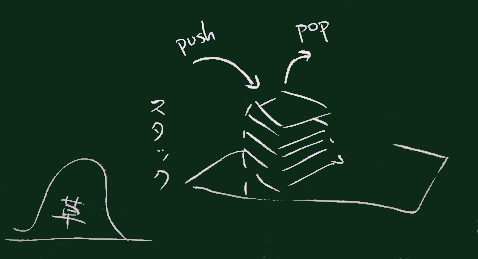
なお、スタックは、右図のようにプログラム(メインの流れ)から 関数(サブプログラム)が呼び出されるときに、 戻り先(を含めて作業途中の状態)を保存しておく場所として 広く使われている。
スタックのLIFO的動作のため、関数呼出が2段3段にまたがっても、 関数実行終了時に正しく戻れることが担保されている。
(参考として)プログラミング言語処理系でのスタックの使われ方を体感するためには、
def x()
x
endといった(無限再帰する)プログラムを実行してみると、 Stack
に関するエラーが発生することを見る事ができるだろう。
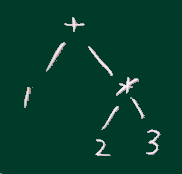
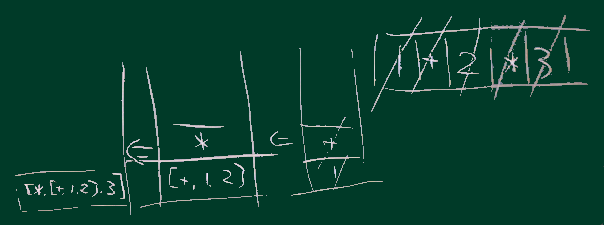
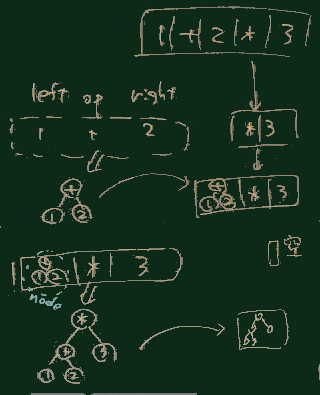
式 1+2*3
は、数学のルールに従うと右右図の木構造として解析されるべきだが、
本項の方式だと右図のようなスタックの動きで ['*',1,['+',2,3]] になる。
 (さらにしっかりしたプログラムにする)
(さらにしっかりしたプログラムにする)
優先度を考慮して構文解析を行うと、その結果の解析木は、 これまで見た例とは違い、(考え方1の右図に示した式 1+2*3 に対して) 右図の形になる。
以下のような手順で解析を行う。
トークンリストが空になるまで以下を繰り返す
とりだした先頭トークン tk が
数字ならば、スタックにpush
演算子ならば スタック[-2]にある演算子(op1と呼んでおく) を見て、 *
1 op1が空(nil)ならば
tk を スタックにpush
2 tkの優先度 > op1の優先度 ならば
tk を スタックにpush
3 そうでなければ( tkの優先度 <= op1の優先度 )
スタックから3つ組を取り出し *
ノードとしてまとめ、
そのノードを再度スタックにpush した上で、
最初に戻る
すべてのトークンを処理したら
スタックから3つ組を取り出し、ノードとして再度push
を繰り返す(3つ組が取り出せなくなるまで)最後にスタックに1つだけ残った要素が、 構文木を表すタプル(多重のタプル)となる。
解析過程でのスタックの状態の変化(黒板図)を別ページに示す。 また、これを実現するプログラム例を以下に示す。
def parse1(tk,a)
puts "#{tk} - #{a}"
case tk
when Numeric then a.push tk # 被演算子
when Symbol then # 演算子
if prior(tk) > prior(op1) then # 優先度が高い => スタックに積む
a.push tk
else # 優先度が低い または同じ優先度
l, op, r = a.pop(3)
a.push [op, l, r]
parse1(tk, a) # 再度呼ぶ(再帰)
end
end
end
def parse(tokenList)
(tokenList+[:END]).each_with_object(a=[]){|tk,a|parse1(tk,a)}
a[-2]
end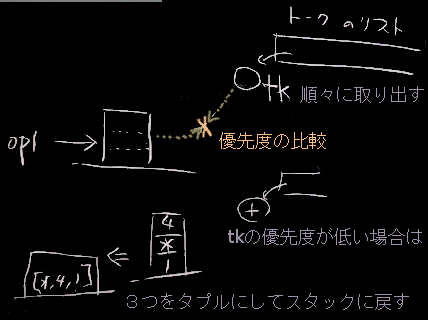

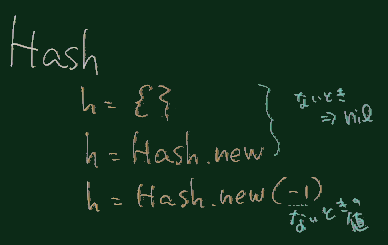
後処理をプログラムするとしたら、
l, op, r = a.pop(3)
a.push [op, l, r]のようなコードを、whileで繰り返すか再帰的に呼ぶか、 という実現方法がある。しかし、
このコードは、前述のコードで「# 優先度が低い または同じ優先度」の時と 同じことをしている。
以下の方法で、この部分が後処理を兼用にすることも可能になる
そのために(ここでは :END と名付けた)特殊な疑似演算子を導入した。
node は、3つの値のタプル(1つの演算を表す;配列で実現)または、終端子(数値)のいずれか。
評価器 val() は、再起的に呼び出される
終端子を受け取ったときはその値をそのまま返す。
タプルを受け取った時は、演算の左右オペランドをそれぞれ評価してから、 その結果の値に対して所定の演算を行い、その結果を返す。
def val(node)
case node
when Numeric then node
else
op,l,r=node
case op
when '+' then val(l)+val(r)
when '-' then val(l)-val(r)
when '*' then val(l)*val(r)
when '/' then val(l)/val(r)
when '%' then val(l)%val(r)
end
end
end例えば以下のような実現方法がある
配列の形で優先度のリストを用意し、それを Hash(連想配列)に予め変換しておく。
演算子(シンボル)の優先度はそのHashを「引く」だけで実現できる
なお、文字列をシンボルにするためには 記号 : を文字列に前置させる。 (通常の文字列だとクオートする必要がないが ( ) = などの文字はクオートする必要がある)
def op2hash(list)
h=Hash.new(-1)
list.each{|e|n=e.shift;e.each{|o|h[o]=n}}
h
end
OPERlist=op2hash([[0,:'(',:')',:END],[1,:'='],[2,:'+',:'-'],[3,:'*',:'/']])
def prior(op) OPERlist[op] end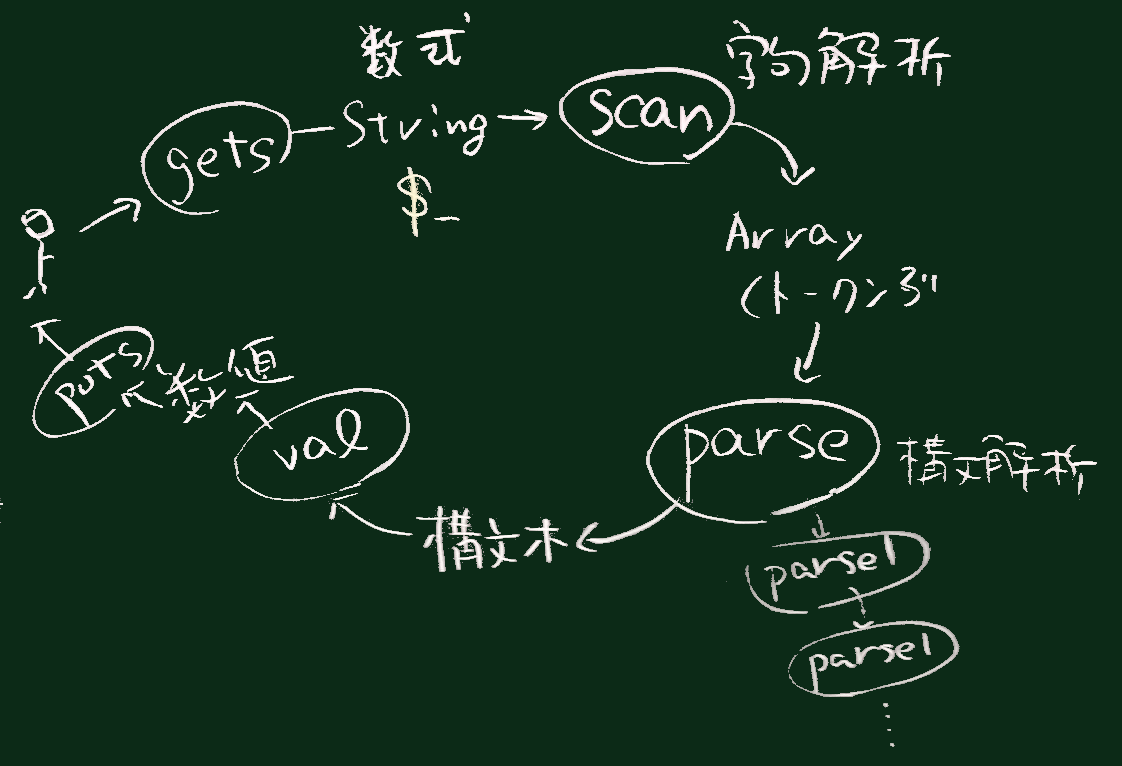
注)
:END が重要な役割を果たしている。:END の優先度を、nil に対する(デフォルトの)
優先度 -1
と同じ値にすると、無限に再帰呼び出しをしてしまうことになる。:END を(nil
よりも高い優先度で)設定しておく必要がある (上の例では
0に設定した)。全体のデータの流れは右図の通り。
def scan(str) # 数式を表す一行の文字列 str を受け取り
...
# トークンの配列を返す
end
def parse(tokenList) # トークンの配列を受け取り
...
# 構文木を返す
end
def val(node) # 構文木(を構成する1つのnode)を受け取り
...
# そのnode(と下位node)を評価(計算)した値 を返す
end
### メインプログラム
while gets do
puts val(parse(scan($_)))
end