情報学概論Ⅱ 第5回
5/19
ファイル 種類 拡張子(2)
1 PDFファイル
(前回のおさらいと補足)
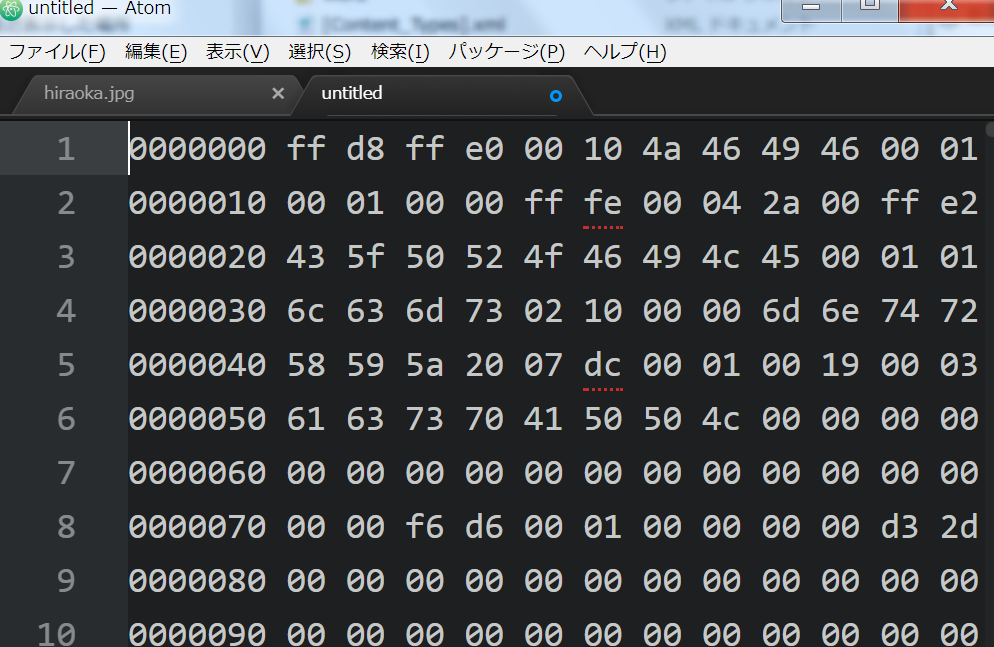
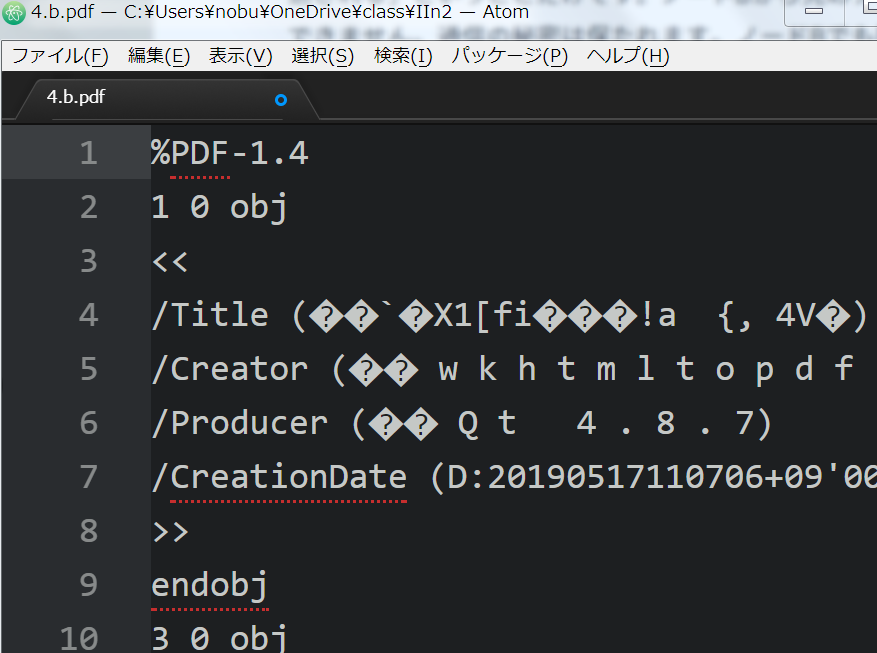
PDFは、テキストファイルとして表示させると右図(の左)のようになっただろう。
- ちなみに、JPEG画像ファイル等は文字として表示できる部分は殆どない
(純粋なバイナリーファイル)。ダンプした結果が右図(の右)。
![PDFの中2]()
- ちなみに、JPEG画像ファイル等は文字として表示できる部分は殆どない
(純粋なバイナリーファイル)。ダンプした結果が右図(の右)。
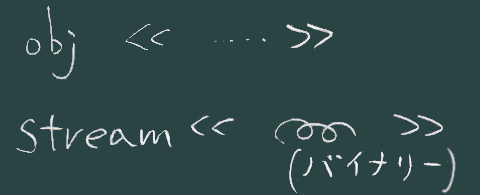
解説と補足:
右図のようなファイルサイズ(大雑把にKB単位)になっており、生成方法による差があることも確認しておいて下さい。
![印刷]() メモ帳<->ブラウザ
メモ帳<->ブラウザ ![印刷:ブラウザの場合]()
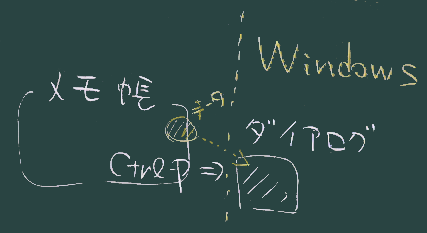 メモ帳<->ブラウザ
メモ帳<->ブラウザ 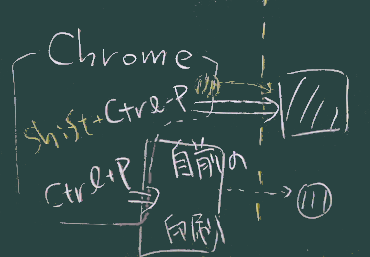
- Webページをブラウザからプリントする際、印刷機能を自前で用意しているブラウザ(たとえばChrome)の場合、自前の印刷機能とWindows組込の印刷機能を使い分けることができる(上図;この2つは機能がかなり違う)。
![ブラウザのフルスクリーンキャプチャ]()
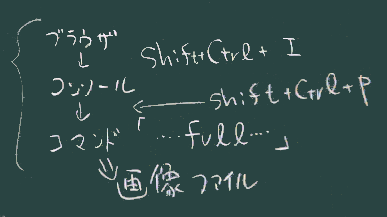
- 上記4.のフルスクリーンキャプチャの機能は広く知られている訳ではない(比較データ生成のために使用しただけで、今回は参考のため紹介したが使う必要も覚える必要もないだろう、 が、参考ページを示しておく 。ただし最近は保存に使う画像形式はpng限定になっているようだ)。
- PDFは(或いは
PostScript言語は)そこに描画すべきものを(画像データを扱う部分を除いて)
線画で表現する。
![アウトライン]()
- アウトラインフォントの表現をページに拡大したもの、をイメージするといいだろう。
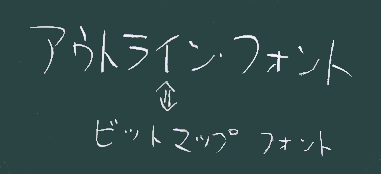
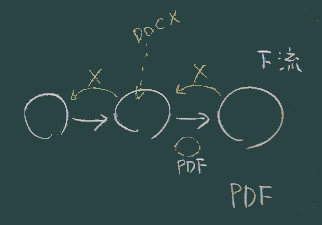
- データの変換は一方通行であることを知っておこう(上図)
- 印刷形式からもとの構造データを復元、画像からテキストへの変換、などは、 (必要な情報が失われているため)技術的に困難。
- データの流れの上流・下流を意識したとき、PDFは下流寄りのデータ形式ということになる。
- なお、前述の pdf writer は最近は(名前が変わって)「Microsoft Print to PDF」と呼ばれているようです。
f. 拡張子が違ったら(または、ついていなければ)
- これまでの知識があれば推測可能
- アプリケーションでの推測
- ポピュラーなのは WinExChange。
![推測サイト]()
- ポピュラーなのは WinExChange。
b. DOCX の実体
- (PDFと同様に)メモ帳で眺めてみる
![操作]()
- よくわからないね
- 実は…

実験:
- DOCXファイル(大事なファイルならばコピーしたものを使う)の、拡張子をzipに変更し、
- それを解凍してみる。
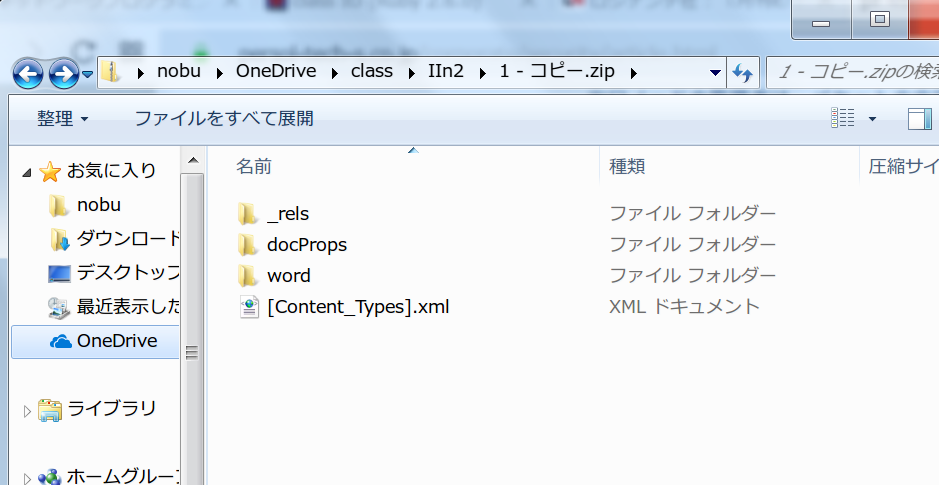
![Officeのファイル形式変遷]() その結果どんなファイルができているか中を覗いてみて下さい。
その結果どんなファイルができているか中を覗いてみて下さい。
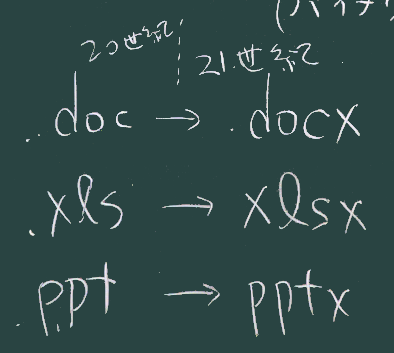 その結果どんなファイルができているか中を覗いてみて下さい。
その結果どんなファイルができているか中を覗いてみて下さい。DOCX(をはじめとする、MicroSoft Officeの 最近のファイル形式;名前にx がつくもの)は、
- このように、複数のファイルをzip形式で圧縮したものである。
- それを構成する各ファイルははXMLの文法で書かれたもの。
ということが推察できるだろう。
![DOCXの実体]()
c. テンプレートの活用(pandocの小技)
テンプレートを作成
pandoc --print-default-data-file reference.docx > reference.docxword(など)でそのスタイルを編集(右図参照)
![スタイルの使用]()
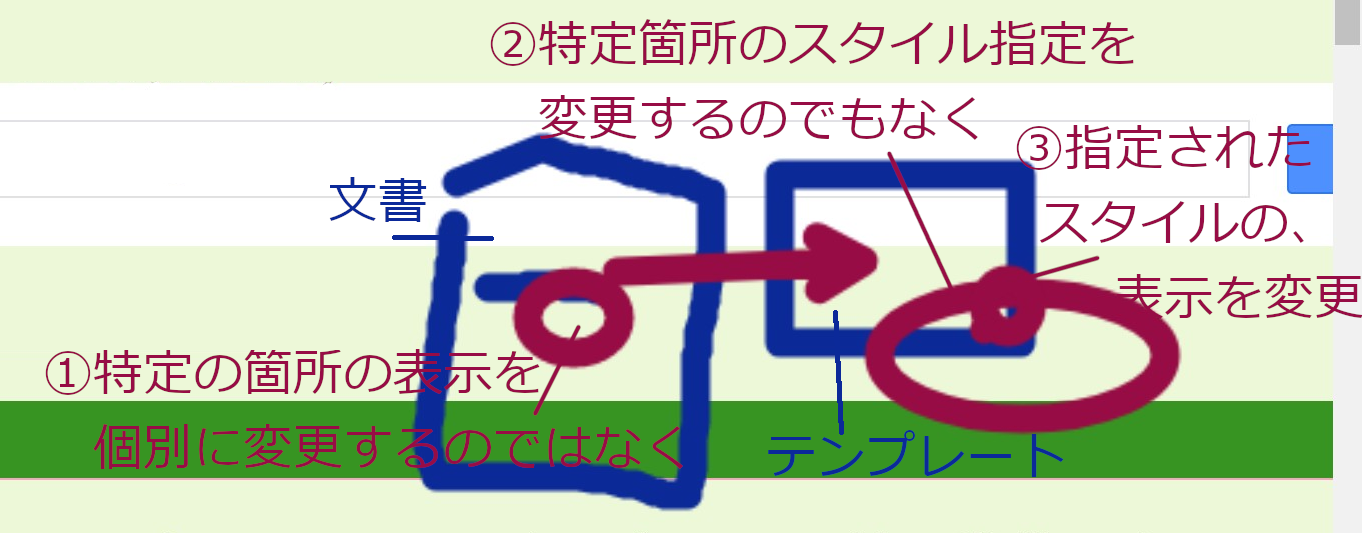
図で示したように、テンプレートファイルの、当該箇所の表示をピンポイントで変更するのではなく、
(それぞれの)スタイル名(を右クリックしてコンテキストメニューから進むといい) の表示形態の「変更」を行う必要がある(ここを誤解する人が多いのでご注意)。
reference.docx- GUI的に開いても勿論かまわないが、ここから開くほうが手っ取り早いだろう。
ちなみに MacOS では
open reference.docx